
11.1 Introduktion til XML 212
11.1.1 XML-formatet 212
11.1.2 DOM - Dokumentets objektmodel 213
11.1.3 XPath - stier i XML-dokumenter 214
11.1.4 Transformering af XML-data (XSL) 214
11.1.5 XML-behandling (SAX og DOM) 215
11.1.6 Dokumenttypedefinitionen 215
11.2 XML-behandling i Java 216
11.2.1 Brug af DOM og XPath 216
11.2.2 Nem generering af XML fra Java-objekter 218
11.3 Syndikering (nyhedsfødning) 219
11.3.1 Nyhedskildernes format 220
11.3.2 Fremvisning med RSS-taglib 222
11.3.3 Fremvisning med Java 223
11.3.4 Syndikering med JSTL 225
11.3.5 Mere information og nyhedskilder på nettet 226
11.4 Principper i metodekald over netværk 227
11.4.1 Systemer til metodekald over netværk 227
11.5 Webtjenester 228
11.5.1 SOAP - kommunikation med webtjenesten 228
11.5.2 WSDL - beskrivelsen af webtjenesten 229
11.5.3 UDDI - offentlige lister over webtjenester 229
11.5.4 Bruge Googles webtjenester til søgninger 229
11.5.5 Genere Java-API fra webtjeneste (WSDL) 230
11.5.6 Generere webtjeneste (WSDL) fra Java-klasse 231
11.5.7 Avanceret: Strukturen i WSDL- og SOAP-filer 232
11.5.8 Yderligere læsning 235
11.6 Test dig selv 235
11.7 Resumé 236
Dette kapitel forudsætter kapitel 3, Interaktive sider. Det er kompakt skrevet og behandler en række avancerede emner, så lidt forhåndskendskab er en fordel.
XML (eXtenisble Markup Language) minder meget om HTML, men har et andet formål:
HTML er beregnet på dokumenter der skal vises for et menneske og det indeholder derfor både tekst og formateringskoder, der instruerer fremviseren (netlæseren) om, hvordan tekstindholdet skal vises.
XML er beregnet til at overføre data mellem programmer - og det indeholder derfor (tekst-)data og koder, der instruerer programmet om, hvordan disse data skal fortolkes.
XML-teknologier har været i en rivende udvikling inden for de seneste par år og emnet kunne nemt fylde en separat bog. Af pladshensyn vil de følgende afsnit derfor blot definere de mest centrale begreber inden for XML og behandle de aspekter, der er relevant i forbindelse med JSP og webserverprogrammering.
En simpel XML-fil kunne se således ud:
persongalleri.xml
<?xml version="1.0" encoding="iso-8859-1"?> <!-- filnavn: persongalleri.xml -->
<galleri>
<titel>Betydningsfulde personer</titel>
<person id="1">
<fornavn>Troels</fornavn>
<efternavn>Nordfalk</efternavn>
<fødselsdato år="1972" måned="08" dag="11" />
</person>
<person id="2">
<fornavn>Jacob</fornavn>
<efternavn>Nordfalk</efternavn>
<fødselsdato år="1971" måned="01" dag="01" />
<værker>
<værk type="bog">
<titel>Objektorienteret programmering i Java</titel>
<isbn udgave="1">8779000940</isbn>
<isbn udgave="2">8779001378</isbn>
</værk>
<værk type="hjemmeside">
<titel>javabog.dk</titel>
<url>http://javabog.dk</url>
</værk>
<værk type="bog">
<titel>Videregående programmering i Java</titel>
<isbn udgave="1">8779001955</isbn>
</værk>
</værker>
</person>
</galleri>En XML-fil er altså en tekstfil med data i nogle navngivne strukturer. Alle koder skal afsluttes igen med en slutkode, som i
<fornavn>Jacob</fornavn>
er der intet mellem start- og slutkoden kan det forkortes ved at afslutte med />, f.eks.:
<fødselsdato år="1971" måned="01" dag="01" />
Denne kode svarer præcist til:
<fødselsdato år="1971" måned="01" dag="01"></fødselsdato>
En af de smarte ting ved XML-formatet (og HTML-formatet) i forhold til andre filformater er, at det kan udvides: Et program der f.eks ikke forstår afsnittet <værker> i ovenstående XML-fil kan nemt springe dette over. På denne måde kan et filformat senere udvides med flere data, uden at det påvirker eksisterende programmer, der bruger filformatet.
Denne egenskab er en af grundene til at HTML blev en succes: efterhånden som netlæserne udviklede sig og kunne fremvise stadigt mere sofistikerede ting, kunne HTML-koden udvides med flere og flere elementer og attributter og stadigvæk være læsbar og vises rimeligt i gamle netlæsere, der ikke forstod de nye elementer og attributter.
XML har gennemgået en rivende udvikling og der er et så stort antal måder at arbejde med XML på, at det kan virke uoverskueligt til at begynde med.
DOM (Document Object Model) er en måde at repræsentere et XML-dokument: Hvert element repræsenteres som et objekt med nogle attributter og underelementer, sådan at dokumentet fremstår som et træ af objekter.
Udviklingsværktøjer kan nemt vise og navigere i DOM-træet. Her ses DOM-træet af persongalleri.xml som Borland JBuilder viser det (nogle grene i træet er foldet sammen):
Her er 'roden' i træet <galleri>, som har 3 'grene' i form af underelementerne <titel>, <person> og <person>, som hver kan have flere underelementer.
XML er så smart indrettet, at man kan angive 'stier' til at finde frem til elementer i et givent dokument. Der er et helt sprog, kaldet XPath, som bruges til at udvælge data i DOM-træet.
Disse stier kan være relative, kan vælge flere elementer og en lang række andre ting.
Her er et par eksempler på XPath-udtryk:
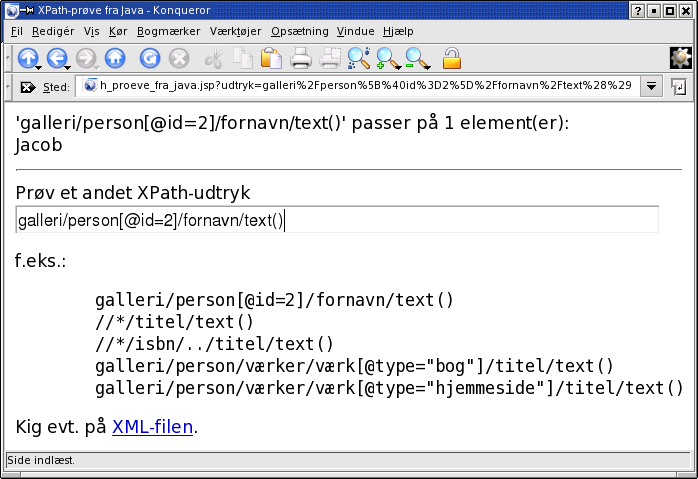
"galleri/person[@id=2]/fornavn/text()" anvendt på ovenstående XML-fil persongalleri.xml vil det finde <galleri>-indgangen, under denne finde <person>-indgangen med attributten id=2 og under den finde <fornavn>-indgangens tekst, d.v.s. strengen:
Jacob
"//*/titel/text()" leder hele træet igennem og finder alle <titel>-koder, uanset hvor det er i DOM-træet:
Betydningsfulde personer
Objektorienteret programmering i Java
javabog.dk
Videregående programmering i Java
"//*/isbn/../titel/text()" leder træet efter <isbn>-koder, går et niveau op (til <værk>) og finder titlen af værket, sådan at man får en liste over alle værker med ISBN:
Objektorienteret programmering i Java
Videregående programmering i Java
"galleri/person/værker/værk[@type="hjemmeside"]/titel/text()" finder alle værker af type hjemmeside og udskriver titlen:
javabog.dk
Ønsker du at vide mere om XPath-udtryk og lave mere avancerede udtryk så se f.eks.:
'How XPath Works' i 'The J2EE 1.4 Tutorial':
http://java.sun.com/j2ee/1.4/docs/tutorial/doc/JAXPXSLT3.html
XML Style Sheet Language (XSL) er en måde at transformere et XML-dokuments data til et hvilken som helst andet tekstformat, f.eks. HTML. Et XSL-dokumenter gør brug af XPath-sproget til at bestemme hvilke dele af XML-dokumentet, der skal ind hvor.
XSL fungerer, populært sagt, lige som god gammeldags brevfletning: XSL-dokumentet er brevfletningsskabelonen, XML-dokumentet er adresselisten. Når de flettes får man breve ud, der ligner skabelonen, men hvor alle felterne i skabelonen er erstattet med data fra XML-dokumentet.
Ønsker du at vide mere om at skrive XSL-transformering så se f.eks.:
'Transforming XML Data with XSLT' i 'The J2EE
1.4 Tutorial':
http://java.sun.com/j2ee/1.4/docs/tutorial/doc/JAXPXSLT6.html
Der findes to fundamentalt forskellige måder at læse en XML-fil på:
SAX (Simple Api for XML processing): Filen gennemløbes fra en ende til en anden, og hvert element, der mødes afstedkommer en hændelse, der skal fanges.
DOM (Document Object Model): Hele filen indlæses og hvert element repræsenteres som et objekt med nogle attributter og underelementer, sådan at dokumentet fremstår som et træ af objekter.
Et program der bruger SAX registrerer en lytter, der får kaldt metoder, mens dokumentet gennemløbes. SAX-måden med seriel læsning er hurtig, har lavt hukommelsesforbrug og er velegnet til at trække nogle data ud at et XML-dokument.
DOM-måden er langsommere og bruger mere hukommelse (da hele dokumentet er repræsenteret i hukommelsen), men kan være mere overskuelig at programmere, da den tillader at man hopper frem og tilbage i objekttræet. Den husker alle elementerne, også dem programmet ikke forstår, og er derfor velegnet til at redigere i XML-dokumenter.
Et XML-dokument kan (men skal ikke) have tilknyttet en beskrivelse af hvilke elementer, der er tilladt i dokumentet. Der findes to måder at definere dokumentformatet:
DTD (Document Type Definition) er en ældre standard.
XML Schema er en nyere standard. XML Schema-dokumenter er i sig selv XML.
DTD er det letteste at læse for mennesker, men XML Schema er lige så stille i gang med at erstatte DTD, bl.a. fordi det kan udtrykke meget mere komplekse regler for dokumenttypens elementer.
Som udvikler kommer man nok aldrig til at læse en dokumenttypedefinition, da der næsten altid er en vejledning henvendt til mennesker, som er meget lettere at læse.
Derfor har de fleste ikke brug for andet end en overfladisk viden om, hvad det er, der skal stå øverst i deres XML-fil, hvis de vil henvise til en dokumenttypedefinition af den ene eller den anden slags.
Webapplikationers driftsbeskrivelsesfil web.xml (se afsnit 7.5) er et eksempel på en XML-fil med en dokumenttypedefinition.
I starten af web.xml-fil i version 2.3 henvises til et DTD:
starten af web.xml i version 2.3 henviser til et DTD
<?xml version="1.0"?> <!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd"> <web-app>
I web.xml i version 2.4 skiftede man over til XML Schema:
starten af web.xml i version 2.4 henviser til et XML Schema
<?xml version="1.0"?>
<web-app xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd"
version="2.4">Er du virkelig interesseret i at se hvordan dokumenttypedefinitioner ser ud kan du se:
Eksempel på DTD på http://java.sun.com/dtd/web-app_2_3.dtd
Eksempel på XML Schema på http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd
Der findes meget stor understøttelse for XML-behandling i Java. Det følgende er derfor kun et par eksempler på, hvordan XML-værktøjerne kan bruges i forbindelse med webprogrammering og JSP.
Her er en JSP-side, der benytter XML-funktioner indbygget i Javas standardbibliotek til at indlæse persongalleri.xml og lade brugeren afprøve forskellige XPath-udtryk til at trække information ud af filen:
<%@page import="org.w3c.dom.*,org.apache.xpath.*,javax.xml.parsers.*" %>
<html>
<head><title>XPath-prøve fra Java</title></head>
<body>
<%
String udtryk = request.getParameter("udtryk");
if (udtryk == null) udtryk = "galleri/person[@id=2]/fornavn/text()";
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// find filen persongalleri.xml i samme mappe som denne JSP-side
String side = application.getRealPath(request.getServletPath());
String fil = side.substring(0, side.lastIndexOf('/')) + "/persongalleri.xml";
// Fortolk XML-koden til et DOM-træ
Document træ = factory.newDocumentBuilder().parse("file:"+fil);
// Lav liste af resultater fra XPath-udtrykket
NodeList res = XPathAPI.selectNodeList(træ, udtryk);
%>'<%= udtryk %>' passer på <%= res.getLength() %> element(er):<br><%
// Gennemløb listen og udskriv
for (int i = 0; i < res.getLength(); i++) {
out.print(res.item(i).getNodeValue()+"<br>");
}
} catch (Exception e) {
e.printStackTrace();
out.print("<p>Der opstod et problem: "+e+"</p>");
}
%>
<hr>
Prøv et andet XPath-udtryk
<form><input name="udtryk" value='<%= udtryk %>' type="text" size="70"></form>
f.eks.:
<pre>
galleri/person[@id=2]/fornavn/text()
//*/titel/text()
//*/isbn/../titel/text()
galleri/person/værker/værk[@type="bog"]/titel/text()
galleri/person/værker/værk[@type="hjemmeside"]/titel/text()
</pre>
Kig evt. på <a href="persongalleri.xml">XML-filen</a>.
</body>
</html>
Ovenstående eksempel bruger XML-funktioner, der findes i JDK1.4. Bruger du en anden version af JDK kan det være at klassen XPathAPI er ukendt. Det skal du så rette op på ved at hente Xalan-Java fra http://xml.apache.org/xalan-j/.
Javabønner (og andre objekter med get- og set-metoder) og almindelige objekter fra Javas standardbibliotek (såsom strenge, ArrayList, Date, ...) kan meget nemt gemmes som XML.
I eksemplet Kalender.java i afsnit 9.4.5 gemmer vi en ArrayList af strenge som XML:
// gem som XML XMLEncoder kal = new XMLEncoder(new FileOutputStream("kalender.xml")); kal.writeObject(liste); kal.close();
Lige så nemt som det er at gemme objekter som XML er det at indlæse dem igen:
// indlæs kalenderen fra XML-fil på disken XMLDecoder kal = new XMLDecoder(new FileInputStream("kalender.xml")); liste = (ArrayList) kal.readObject(); kal.close();
Kigger man i filen kalender.xml på harddisken ser man at den indeholder
<?xml version="1.0" encoding="UTF-8"?> <java version="1.4.2_03" class="java.beans.XMLDecoder"> <object class="java.util.ArrayList"> <void method="add"> <string></string> </void> <void method="add"> <string>Undervise</string> </void> <void method="add"> <string></string> </void> <void method="add"> <string></string> </void> <void method="add"> <string>Holde fri</string> </void> </object> </java>
Bemærk at klasserne XMLEncoder og XMLDecoder ikke kan anvendes til at konvertere hvad som helst til og fra XML. Specielt skal man være opmærksom, hvis man ønsker at gemme sine egne klasser: De skal være javabønner og alle data i objektet, man ønsker gemt, skal være egenskaber (se afsnit 9.2.2, Egenskaber på en javabønne).
Ønsker man at gemme alle slags objekter er serialisering med ObjectOutputStream og ObjectInputStream, der f.eks. er beskrevet på http://javabog.dk en bedre løsning.
// gem som serialiseret objekt (ikke XML)
ObjectOutputStream kal = new ObjectOutputStream(
new FileOutputStream("kalender.ser"));
kal.writeObject(liste);
kal.close();og de-serialisering:
kal = new ObjectInputStream(new FileInputStream("kalender.ser"));
liste = (ArrayList) kal.readObject();
kal.close();Ulempen med serialisering er, at filen med de gemte objekter (kalender.ser) er i et binært format, der meget vanskeligt kan læses på anden måde end ved at deserialisere det i Java.
Indholdssyndikering (eng.: content syndication) går kort sagt ud på at hente information (f.eks. nyheder) fra andre hjemmesider og vise det på sin egen.
Syndikering kan give liv i en hjemmeside og anvendes rigtig meget på næsten alle internetportaler, når de på forsiden viser f.eks. vejrudsigter og nyheder og anden information, som de ikke selv producerer, men henter fra andre steder på nettet.
Syndikering forkortes RSS, der står for (afhængigt af hvem man spørger :-) Really Simple Syndication, Rich Site Summary eller RDF Site Summary. Teknologien udsprang af RDF (Resource Description Framework), et system Netscape oprindelig introducerede.
Informationen fra den anden hjemmeside skal være i et bestemt XML-format. For eksempel Java-nyheder fra Sun:
eksempel fra http://servlet.java.sun.com/syndication/rss_java_highlights.xml på RSS-fil med nyheder
<?xml version="1.0"?> <rss version="0.91"> <channel> <title>java.sun.com</title> <link>http://java.sun.com/</link> <description>java.sun.com is the premier source of information about the Java platform.</description> <language>en-us</language> <copyright>Copyright: (C) 1995-2003 Sun Microsystems, Inc.</copyright> <image> <title>java.sun.com</title> <url>http://java.sun.com/images/v4_java_logo.gif</url> <link>http://java.sun.com/</link> <width>38</width> <height>66</height> <description>Visit java.sun.com</description> </image> <item> <title>Play Ball!</title> <link>http://servlet.java.sun.com/logRedirect/rss_java_highlights/http://developer.java.sun.com/developer/technicalArticles/ThirdParty/Tendu/</link> <description>Tendu's Java software applications give Major League baseball teams instant insight -- and maybe even a competitive advantage. </description> </item> <item> <title>Toward a Global "Internet of Things"</title> <link>http://servlet.java.sun.com/logRedirect/rss_java_highlights/http://developer.java.sun.com/developer/technicalArticles/Ecommerce/rfid/index.html</link> <description>Everything you buy, consume, and enjoy--even trees!--may soon be tagged with a unique ID. Learn all about the Java technology that is propelling the Internet ever further into the physical world. </description> </item> ... (flere <item>-indgange) </channel> </rss>
Her kunne man f.eks. bruge XPath-udtrykket 'rss/channel/description/text()', for at få beskrivelsen af nyhedskilden (der er: 'java.sun.com is the premier source of information about the Java platform.').
Ovenstående er RSS version 0.91. Det præcise format har gennem tiden ændret sig lidt, så på nettet kan man finde nyhedskilder i RSS-format version 0.91, 0.92, 1.0 og 2.0. De enkelte versioner adskiller sig ikke meget fra hinanden, men DOM-træerne kan være lidt forskellige, så man skal lige tjekke om nyhederne kommer korrekt over på ens egen side.
Her er et eksempel på en RSS-fil version 1.0 med nyheder fra Danmark Radio:
eksempel fra http://www.dr.dk/nyheder/html/nyheder/rss/ på RSS-fil version 1.0 (nogle af indgange er fjernet)
<?xml version="1.0" encoding="iso-8859-1"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns="http://purl.org/rss/1.0/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:taxo="http://purl.org/rss/1.0/modules/taxonomy/" xmlns:syn="http://purl.org/rss/1.0/modules/syndication/"> <channel rdf:about="http://www.dr.dk/nyheder/"> <title>DR Nyheder Online</title> <link>http://www.dr.dk/nyheder/</link> <description>Velkommen til DR Nyheder på nettet: Nyheder opdateret 24 timer i døgnet. © DR 2003</description> <dc:language>da</dc:language> <items><rdf:Seq> <rdf:li rdf:resource="http://www.dr.dk/nyheder/indland/article.jhtml?articleID=194577" /> <rdf:li rdf:resource="http://www.dr.dk/nyheder/indland/article.jhtml?articleID=194567" /> <rdf:li rdf:resource="http://www.dr.dk/nyheder/udland/article.jhtml?articleID=194574" /> <rdf:li rdf:resource="http://www.dr.dk/nyheder/indland/article.jhtml?articleID=194569" /> <rdf:li rdf:resource="http://www.dr.dk/nyheder/indland/article.jhtml?articleID=194553" /> </rdf:Seq></items> <item rdf:about="http://www.dr.dk/nyheder/indland/article.jhtml?articleID=194577"> <title>Læger truer med sygehusstrejke</title> <link>http://www.dr.dk/nyheder/indland/article.jhtml?articleID=194577</link> <description>En alvorlig konflikt truer med at lamme dele af det vestsjællandske sundhedsvæsen, efter at 70 ledende medarbejdere på tre sygehuse i Vestsjællands Amt har klaget til amtspolitikerne over to medicinske chefer.</description> </item> <item rdf:about="http://www.dr.dk/nyheder/indland/article.jhtml?articleID=194567"> <title>Sverige - et smuthul for tvangsægteskaber</title> <link>http://www.dr.dk/nyheder/indland/article.jhtml?articleID=194567</link> <description>Hver måned flytter mellem 48 og 64 unge nydanskere til Sverige for at blive familiesammenført med en borger fra et ikke-EU-land, som de på grund af den danske 24-års-regel ikke kan blive sammenført med i Danmark. Siden vender de tilbage til Danmark.</description> </item> <item rdf:about="http://www.dr.dk/nyheder/udland/article.jhtml?articleID=194574"> <title>To franske journalister gidsler i Irak</title> <link>http://www.dr.dk/nyheder/udland/article.jhtml?articleID=194574</link> <description>Irakiske bortførere har givet Frankrig 48 timer til at gå ind på deres krav, hvis de skal skåne to franske journalister, som blev bortført forleden. Bortførerne kræver, at Frankrig ophæver loven fra foråret, der forbyder muslimske piger at bære hovedtørklæde i franske skoler.</description> </item> <item rdf:about="http://www.dr.dk/nyheder/indland/article.jhtml?articleID=194569"> <title>Advarsel mod sød yoghurtdrik</title> <link>http://www.dr.dk/nyheder/indland/article.jhtml?articleID=194569</link> <description>Ernæringseksperter advarer mod Arlas søde yoghurtdrik Cultura, som de kalder for slik forklædt som yoghurtdrik, fordi drikken indeholder næsten lige så meget sukker som sodavand. Topscoreren er vaniljedrik, der indeholder svarende til 21 sukkerknalder.</description> </item> </rdf:RDF>
Sammenligner man ovenstående med eksemplet med Java-nyheder, ser man at DOM-træet er lidt anderledes. Man skal f.eks. bruge 'RDF/channel/description/text()' som XPath-udtryk (med RDF i stedet for rss) for at få beskrivelsen ('Nyheder Danmarks Radio')1.
Lad os nu se på, hvordan man kan indflette andres nyheder i sine egne sider.
Hvis man ikke har mod på selv at skrive koden, der henter og behandler XML-filerne kan man på http://java.sun.com/developer/technicalArticles/javaserverpages/rss_utilities/ få et JSP taglib-bibliotek der tillader RSS-fødning (af kilder med RSS version 0.91, 0.92 og 2.0) til en webside. Et tag library (forkortet taglib) er, som navnet antyder, et bibliotek af HTML-lignende koder. Ligesom JSP-koderne udføres disse på serveren, sådan at klienten aldrig ser dem.
På hjemmesiden er også beskrevet, hvordan taglib-biblioteket installeres. Dette er en rimelig nem procedure: Hent ZIP-filen, læg rssutils.jar ind i WEB-INF/lib/ i webapplikationen og rssutils.tld ind i WEB-INF/.
Herunder er et simpelt eksempel på brug af RSS-taglibbet:
<%@ taglib uri="/WEB-INF/rssutils.tld" prefix="rss" %> <html> <head><title>Syndikering med RSS-taglib</title></head> <body> <h1>Java-nyheder</h1> <rss:feed feedId="nyh" url="http://servlet.java.sun.com/syndication/rss_java_highlights.xml" /> <rss:forEachItem feedId="nyh"> <a href='<rss:itemLink feedId="nyh"/>'><rss:itemTitle feedId="nyh"/></a> <font size="-1"> <rss:itemDescription feedId="nyh"/> </font><br> </rss:forEachItem> Kilde:<rss:channelTitle feedId="nyh"/><br> <h1>Trådløse nyheder</h1> <rss:feed feedId="traadl" url="http://servlet.java.sun.com/syndication/rss_wireless_highlights.xml" /> <rss:forEachItem feedId="traadl"> <rss:itemTitle feedId="traadl"/> (<a href='<rss:itemLink feedId="traadl"/>'>læs mere</a>)<br> </rss:forEachItem> </body> </html>
Denne side producerer følgende skærmbillede, med nyheder fra to nyhedskilder (Java-nyheder og nyheder om trådløse apparater) præsenteret lidt forskelligt neden under:
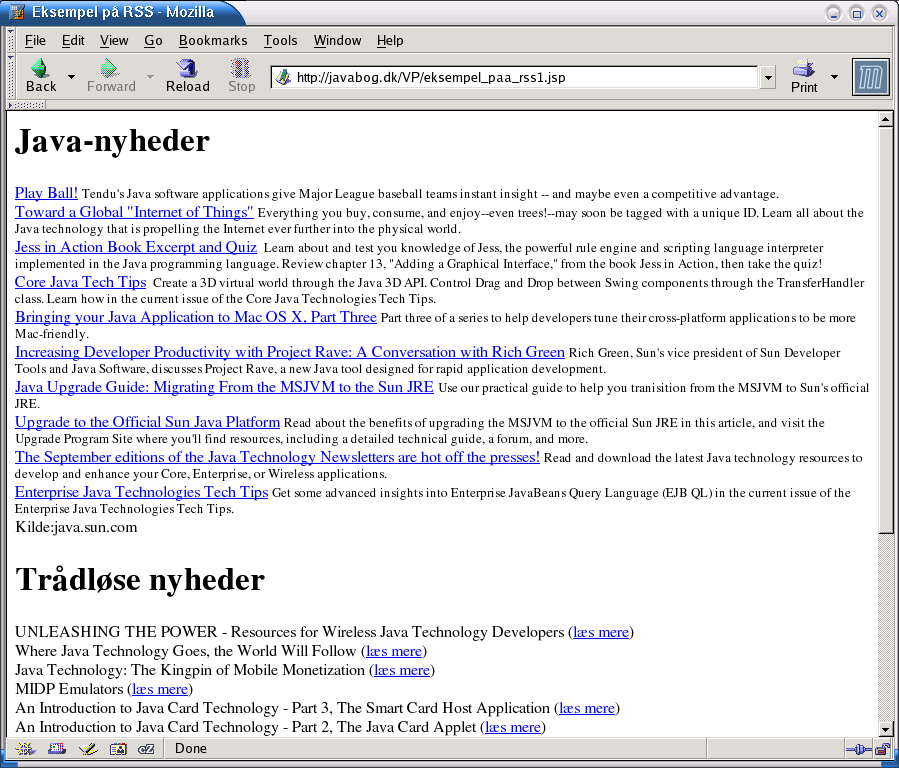
Har du mod på selv at arbejde med XML, kan du benytte Javas indbyggede funktioner til at udvælge informationer fra en RSS-nyhedkilde med XPath og flette dem ind i dine sider.
Det følgende eksempel fletter nyheder fra Danmarks Radio ind i siden:
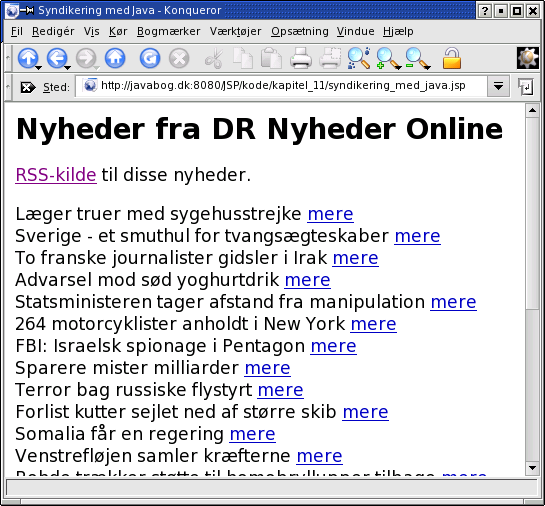
<%@page import="org.w3c.dom.*,org.apache.xpath.*,javax.xml.parsers.*" %>
<html>
<head><title>Syndikering med Java</title></head>
<body>
<%
String kilde = request.getParameter("kilde");
if (kilde == null) kilde = "http://www.dr.dk/nyheder/html/nyheder/rss/";
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// Fortolk kildens XML-kode til et DOM-træ
Document træ = factory.newDocumentBuilder().parse(kilde);
// Find titlen på nyhedskilden med XPath-udtryk
Node titel = XPathAPI.selectSingleNode(træ, "RDF/channel/title/text()");
%>
<h1>Nyheder fra <%= titel.getNodeValue() %></h1>
<a href="<%= kilde %>" type="application/rss+xml">RSS-kilde</a> til disse nyheder.
<p>
<%
// Lav liste med overskrifter på artikler med XPath-udtryk
NodeList overskrifter = XPathAPI.selectNodeList(træ, "RDF/item/title/text()");
// Lav liste over henvisninger til mere læsninger med XPath-udtryk
NodeList henvisninger = XPathAPI.selectNodeList(træ, "RDF/item/link/text()");
// Gennemløb listerne og udskriv dem
for (int i = 0; i < overskrifter.getLength(); i++) {
out.print(overskrifter.item(i).getNodeValue());
out.print(" <a href="+henvisninger.item(i).getNodeValue()+">mere</a><br>");
}
 } catch (Exception e) {
e.printStackTrace();
out.print("Et problem opstod: "+e);
}
%>
<p>
Prøv en anden nyhedskilde
<form>
<input type="text" name="kilde"
value="http://slashdot.org/index.rss"
size="40">
</form>
</body>
</html>
} catch (Exception e) {
e.printStackTrace();
out.print("Et problem opstod: "+e);
}
%>
<p>
Prøv en anden nyhedskilde
<form>
<input type="text" name="kilde"
value="http://slashdot.org/index.rss"
size="40">
</form>
</body>
</html>
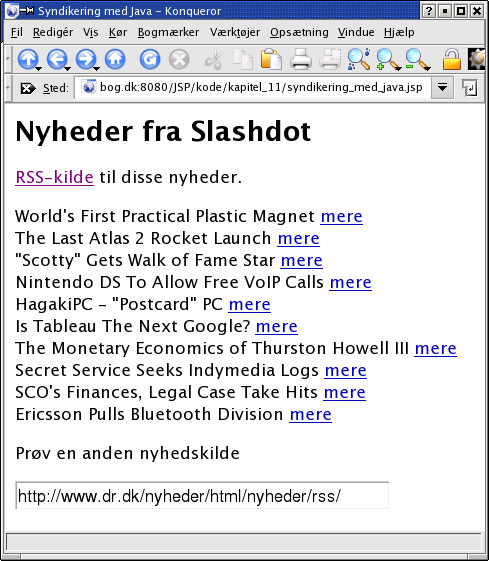
Eksemplet tillader at man kan ændre
nyhedskilde. På billedet til højre hentes nyhederne i
stedet fra Slashdot (der leverer nyheder for nørder).
Man kan også udnytte JSTL til syndikering. I afsnit 6.4.1 vises et eksempel, der indfletter nyheder fra Danmarks Radio ved hjælp af JSTLs XML-funktioner:
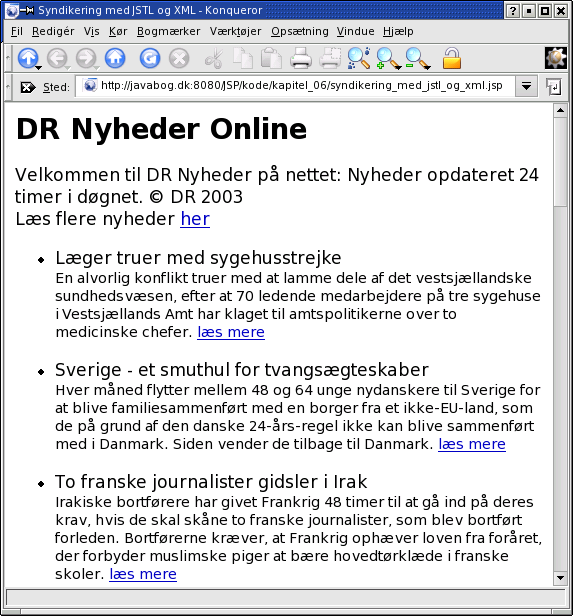
I afsnit 6.4.2 er også nævnt lidt om caching af nyhedskilder, som er relevant at overveje, hvis man for alvor vil gøre brug af syndikering.
XPath-udtrykkene i afsnit 6.4.1 er desværre lidt knudrede:
<x:out select="$rss//*[name()='channel']/*[name()='title'][1]"/>
Det skyldes at JSTLs XML-behandling endnu ikke fuldt understøtter brug af namespaces, som RSS version 1.0 benytter (det er de mange xmlns:-koder i toppen af DRs RSS-fil).
Det kunne egentlig være skrevet så enkelt som (RSS 1.0):
<x:out select="$rss/RDF/channel/title/text()"/>
eller (RSS 0.91, hvor DOM-træets rod hedder rss og ikke RDF):
<x:out select="$rss/rss/channel/title/text()"/>En fordel ved de knudrede XPath-udtryk er dog, at de faktisk fungerer for alle RSS-versionerne, uanset om hele molevitten nu engang ligger under 'RDF' eller 'rss' i DOM-træet.
Se http://www-106.ibm.com/developerworks/java/library/j-jstl0520 for mere information om brug af JSTL til RSS-syndikering.
Using RSS in JSP pages: http://today.java.net/pub/a/today/2003/08/08/rss.html
Der findes utallige nyhedskilder på nettet, og der kommer dagligt flere til.
Ofte vil et websted vise et
lille XML-ikon nederst på siden for at gøre opmærksom
på at dens indhold kan syndikeres. Det ser sådan her ud:
 .
.
Her er et par websteder med RSS og URLen til deres nyhedsfødning:
DR Nyheder: http://www.dr.dk/nyheder/html/nyheder/rss/
Dagbladet Information http://rss.asdf.dk/information.rss
Alt Om København: http://rss.asdf.dk/aok.rss
Børsen Online: http://rss.asdf.dk/borsen.rss
Slashdot: http://slashdot.org/slashdot.rdf
Java-nyheder: http://servlet.java.sun.com/syndication/rss_java_highlights.xml
Trådløs Java: http://servlet.java.sun.com/syndication/rss_wireless_highlights.xml
Her er et par steder, der holder styr på de danske websteder med RSS-fødning:
I dette afsnit vil vi beskrive en måde at arbejde med objekter, der eksisterer på en anden fysisk maskine, som om de var lokale objekter.
Herunder er tegnet, hvad der sker, når en klient på maskine A laver et metodekald i et serverobjekt (da: værts-objekt), der befinder sig på maskine B:
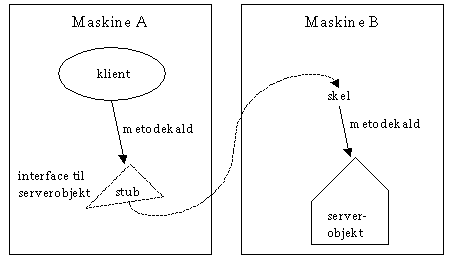
Serverobjektet findes slet ikke på maskine A, i stedet er der en såkaldt stub, et proxy-objekt, der repræsenterer det rigtige objekt på serveren.
Når der sker et kald til stubben på maskine A, sørger den for at transportere kaldet og alle parametre til maskine B, hvor serverobjektet bliver kaldt, som om det var et lokalt kald. Serverobjektets svar bliver transporteret tilbage til stubben, der returnerer svaret til klienten.
Denne proces foregår helt automatisk og er usynlig for klienten såvel som serverobjektet.
For at kunne transportere parametre og returværdi mellem maskinerne, skal alle data, der sendes over netværket, kunne omsættes til en række byte af systemet ('serialiseres').
I dag findes der mange måder, hvorpå man kan lave systemer, der kan håndtere program-til-program kommunikation, bl.a. RMI, EJB, webtjenester, CORBA eller DCOM.
Det er ovenstående princip, der bruges i alle disse systemer.
RMI, Remote Method Invocation er meget nemt at benytte. Det bygger på Java, så både klientdel og serverdel skal skrives i Java. RMI benytter Java-serialisering (der er et binært format), når det sender data mellem klient og server. Man kan ikke forvente, at kunne kalde metoder i et RMI-objekt uden for lokalnettet, da RMI benytter andre porte end HTTP-protokollen (næsten alle firewalls har åbnen på port 80, som HTTP-protokollen benytter sig af).
CORBA, Common Object Request Broker Architecture, er sproguafhængig (så objekterne behøves ikke skrives i Java), men er svært at bruge, der skal genereres et væld af filer og CORBAs beskrivelse af fjernobjekternes metoder, IDL (Interface Definition Language), er svært at forstå.
EJB, Enterprise JavaBeans, der er beskrevet i kapitel 12, benytter RMI eller CORBA.
Webtjenester, beskrevet i næste afsnit, er sprog- og platformsuafhængigt, benytter XML i stedet for binære protokoller og kan benytte HTTP-protokollen til at transportere metodekald (så kommunikationen slipper igennem firewalls).
DCOM, Distributed Common Object Model, er Microsofts måde at kommunikere fra et program til et andet. Selvom programmeringssprogene kan variere, er det kun programmeringssprog, der er kompatible på en Microsoft-platform, der kan benyttes, såsom Visual Basic, C++ osv. Det samme gælder for klientprogrammerne, der også skal ligge på Microsoft-platforme.
Webtjenester (eng.: Web services) så dagens lys første gang i starten af 2002 og er udviklet af Sun Microsystems, da de lancerede deres første udgave af Java Web Services Developer's Pack (JWSDP).
En webtjeneste er et system til program-til-program kommunikation på tværs af netværk. Man kommunikerer med en webtjeneste ved at sende og modtage SOAP-meddelelser (XML-dokumenter, se senere), som skal overholde det format, der er fastlagt i beskrivelsen af webtjenesten (WSDL, se senere). SOAP-meddelelserne overføres typisk med HTTP-protokollen. Webtjenester kan være registreret offentligt (UDDI, se senere).
Kommunikationen mellem en klient og en webtjeneste foregår med SOAP (Simple Object Access Protocol), hvor meddelelserne mellem klient og server er små XML-dokumenter i bestemt format.
SOAP er hverken system- eller programmeringssprogsafhængigt: Både webtjenesterne og de klienter, der bruger dem, kan skrives på alle mulige platforme såsom Linux, Mac eller Windows og med forskellige programmeringssprog såsom Java, C++, Perl, Python, ASP eller PHP. En webtjeneste og de tilhørende klienter behøver ikke at være skrevet i det samme programmeringssprog, så længe kommunikationen mellem dem overholder den struktur, der er beskrevet i webtjenestens WSDL.
WSDL står for Web Service Definition Language. Det er et XML-dokument, der beskriver en webtjeneste i detaljer. I WSDLen til en webtjeneste kan man se webtjenestens URL - den adresse, hvor webtjenesten udbydes, hvilke metoder webtjenesten stiller til rådighed, hvilke parametre, som webtjenestens metoder tager i en forespørgsel og hvilke parametre webtjeneste svarer tilbage med på en forespørgsel.
Hvis man vil danne sine egne stubbe til at tilgå en webtjeneste, skal man have fat i webtjenestens WSDL, så man kan se, hvad metoderne hedder, og hvordan de skal forespørges.
Der findes mange programmer, der automatisk kan danne stubbene ud fra et WSDL. Hvordan man gør i Oracle JDeveloper og Apache Axis er omtalt i afsnit 11.5.5, Genere Java-API fra webtjeneste (WSDL).
Skal man udgive sin webtjeneste til offentlig brug, kan det være smart at udgive den i en slags telefonbog, som De Gule Sider. Brugere kan slå op i denne 'telefonbog' for at finde en tjeneste, der dækker deres behov. Her kan de finde URLen på webtjenesten, webtjenestens WSDL og en beskrivelse af, hvad webtjenesten kan gøre for dem. Der er et par af de store IT-firmaer, der stiller en sådan telefonbog til rådighed blandt andet Microsoft og IBM.
F.eks. kan man finde de webtjenester, som internet-boghandlen Amazon stiller til rådighed, på: https://uddi.ibm.com/ubr/findservice?action=details&servicekey=BA6D9D56-EA3F-4263-A95A-EEB17E5910DB.
En sådan telefonbog over webtjenester kaldes for UDDI, som står for Universal Description and Discovery Integration. Fordelen ved at få listet sine webtjenester i UDDIerne er at de bliver kendt et sted, hvor brugerne ved, de skal kigge efter dem.
Gå ind på UDDI-siden http://uddi.xmethods.net/ og læs om de forskellige webtjenester.
På siden er også en grænseflade, som kan bruges til at prøve at kalde nogle af webtjenesterne. Prøv også den.
Google har en webtjeneste, som tillader udviklere at skrive programmer, der kan søge i de milliarder af dokumenter, som Google indekserer.
Gå ind på http://google.com/apis og læs om Google Web APIs og hent udviklingskittet.
Du skal også bruge en nøgle, som du kan få ved at registrere dig. Nøglen er en lang streng som f.eks.: VkjZ2P5QFHICg5MfvjuwzmJm1T/iYbdY
Det letteste er at bruge Googles
Java-programmeringsgrænseflade (API) til webtjenesten.
Pak
filen ud og prøv demoen, der ligger i googleapi.jar. Prøv
f.eks. fra kommandolinjen at søge på "Den lille
havfrue" (skriv på en enkelt linje - husk at udskifte med
din egen nøgle):
java -cp googleapi.jar com.google.soap.search.GoogleAPIDemo
VKjZ2P5QFHICg5MfvjuwzmJm1T/iYbdY search "Den lille havfrue"
Ud skulle gerne komme en masse adresser på sider om den
lille havfrue, f.eks.:
Parameters:
Client key = VkjZ2P5QFHICg5MfvjuwzmJm1T/iYbdY
Directive = search
Args = Den lille havfrue
Google Search Results:
======================
{
TM = 0.367159
Q = "Den lille havfrue"
Start Index = 1
End Index = 10
Estimated Total Results Number = 7590
Rs =
{
[
URL = "http://hjem.get2net.dk/OSJ_INDEX/hybenrose/havfruen/"
Title = "<b>Den</b> <b>lille</b> <b>Havfrue</b>"
Snippet = "En beretning om Danmarks nationale vartegn, <b>Den</b> <b>lille</b> <b>Havfrue</b> ved Langelinie - Fakts<br> om havfruen, eventyret, skulpturen, og de mange hærværk - billeder fra <b>...</b> "
Summary = "Uofficiel side om <b>Den</b> <b>lille</b> <b>Havfrue</b> ved Langelinie - Fakts om havfruen, eventyret, skulpturen, og..."
Cached Size = "10k"
],
[
URL = "http://hjem.get2net.dk/chenero/hca/hcaev008_da.html"
Title = "<b>Den</b> <b>lille</b> <b>havfrue</b>"
Snippet = "<b>Den</b> <b>lille</b> <b>havfrue</b>. af Hans Christian Andersen. <b>...</b> ?Det gør ondt!? sagde <b>den</b> <b>lille</b> <b>havfrue</b>.<br> ?Ja man må lide noget for stadsen!? sagde <b>den</b> gamle. Oh! <b>...</b> "
Summary = ""
Cached Size = "47k"
],
[
URL = "http://www.hcandersen-homepage.dk/skulptur_den_lille_havfrue.htm"
Title = "HC Andersen: Skulptur "<b>Den</b> <b>lille</b> <b>havfrue</b>""
Snippet = "..... Skulptur "<b>Den</b> <b>lille</b> <b>havfrue</b>". hans christian andersen homepage odense<br> denmark. ..... <b>...</b> <b>den</b> <b>lille</b> <b>havfrue</b> - "The mermaid", Havfruen. <b>...</b> "
Cached Size = "14k"
],
}
}
Du kan også genere APIet i dit eget sprog ud fra webtjenestebeskrivelsen (WSDL) med et værktøj. Herunder er beskrevet, hvordan et API kan genereres i Java ud fra en webtjeneste med Oracle JDeveloper og Apache Axis.
Åbn beskrivelsen af tjenesten (WSDL-filen), højreklik på den og vælg "Generate Web Service Stub/Skeleton" og generér en klient-side stub med en main()-metode.
I Apache Axis' API kan man få dannet en WSDL på to måder:
Den ene måde er, at
idriftsætte sin webtjeneste ud fra en XML-fil, som er en
WSDD-fil, WebService Definition Document. Axis vil derefter starte
webtjenesten og danne WSDL-filen. Man kan derefter se filen, ved at
skrive webtjenestens URL i adressefeltet på sin
netlæser, men efter webtjenestens navn tilføje
parameteren wsdl, f.eks.:
http://localhost:8080/jboss-net/services/Veksletjeneste?wsdl
Man kan også benytte det medfølgende program, Java2WSDL, som kan producere WSDL-dokumentet ud fra den Java-klasse, som man vil udbyde som en webtjeneste. Programmet Java2WSDL tager 3 parametre, ud over Javaklassens fulde navn: Navnet på WSDL-filen, webtjenestens URL og et "target namespace", som skal være et entydigt navn på webtjenesten.
Gør ovenstående med Googles WSDL-fil (GoogleSearch.wsdl). Kig filerne igennem og gå derpå ind i GoogleSearchServiceStub og ret main() til:
// opret stubben GoogleSearchServiceStub stub = new GoogleSearchServiceStub(); // foretag søgningen GoogleSearchResult sr=stub.doGoogleSearch("VKjZ2P5QFHICg5MfvjuwzmJm1T/iYbdY", "Den lille havfrue",new Integer(0),new Integer(10), Boolean.FALSE,null,Boolean.FALSE,null,null,null); // gennemløb resultaterne ResultElement[] re = sr.getResultElements(); for (int i=0; i<re.length; i++) System.out.println(re[i].getTitle() +" "+re[i].getURL());
... og kør programmet (husk at udskifte nøglen med din egen nøgle). Ud skulle gerne, som før, komme en række adresser på sider om den lille havfrue.
Opret eller find en simpel klasse med nogle metoder, du kunne tænke dig at udbyde som en webtjeneste.
Lav f.eks. en klasse, der kan konvertere mellem dollar og euro:
package webtjeneste;
public class Veksler
{
public double euroTilDollar(double euro)
{
System.out.println("euroTilDollar("+euro+") kaldt!");
return euro/1.1;
}
public double dollarTilEuro(double dollar)
{
System.out.println("dollarTilEuro("+dollar+") kaldt!");
return dollar*1.1;
}
}Højreklik derefter på klassen og vælg 'Create J2EE Web Service'.
Dobbeltklik på den genererede fil og giv tjenesten et navn (f.eks. navnet MinTjeneste).
Højreklik på filen og vælg 'Run'
... og du har en webtjeneste kørende!
Tjenesten kører i Oracle JDevelopers interne webserver. For at afprøve den, kan du genere en Java-klient fra WSDL-webtjenestebeskrivelsen, som beskrevet i forrige afsnit.
Axis stiller et program til rådighed, der kan danne Javastubbene til kommunikation med en webtjeneste ud fra webtjenestens WSDL. Dette program hedder WSDL2Java og tager to parametre: et pakkenavn til stub-klasserne og filnavnet på WSDL-filen.
Suns portal om webtjenester:
http://java.sun.com/webservices/
Apache-gruppens
implementering af webtjenester (Axis):
http://ws.apache.org/axis/java/
Oracle JDeveloper har
meget kraftig understøttelse af webtjenester. En lang række
artikler om webtjenester og Oracle JDeveloper kan ses på
http://www.oracle.com/technology/tech/webservices/htdocs/series/
og
http://www.oracle.com/technology/tech/webservices/
Søgeportalen Googles webtjenester:
http://www.google.com/apis/
E-handelssiden Amazons webtjenester:
http://soap.amazon.com/
Auktionssiden Ebays
webtjenester:
http://developer.ebay.com/DevProgram/
Liste over firmaer, der udbyder
webtjenester:
http://uddi.xmethods.net/
1Vigtigste forskel er nok at <item>-indgangene i RSS 1.0 er sideordnet med <channel>, hvor de i version 0.91 ligger under <channel>-indgangen.